Form-based collaborative editing
Your team works in forms generated from your Schemas: typed fields, dropdowns, and pickers for the links between Subjects. The Schema's constraints are checked as they edit, so structure holds at the point of entry. No syntax to learn.
Structured records and prose share the page: same diffs, same change notifications, same review workflows. One record can describe several related entities, such as a project, its team, and a recent milestone, without losing the boundaries between them.
People, scripts, the REST API, and AI agents all write through the same validated path, so nothing reaches the graph unchecked.
Schemas as a contract
A Subject is a structured entity, such as a person or a product. Each Schema defines one Subject type: its fields, their types, constraints, and defaults. Constraints are checked wherever data is written: editors, scripts, the API, AI agents.
Schemas evolve without migrations. When a Schema changes, past edits keep their original meaning: a renamed property or a new constraint does not silently rewrite history. Schema edits are tracked and reversible, like any other change.
A graph database, queried in standard languages
Your structured data lives in a graph database, kept in sync as you edit. The graph is the right shape for questions about how things connect: who's connected to whom, what depends on what, what's reachable from where.
Cypher is the query language today, available in pages and via REST. SPARQL via QLever is next. Both return structured data your templates and applications can use directly.
MATCH (c:Company)
WHERE c.`Founded at` > 2010
RETURN c.name, c.`Founded at`
ORDER BY c.`Founded at` DESCAI-ready by construction
Your AI grounds on the same substrate your editors maintain: Schemas, validation, revision history, the graph itself.
Retrieval-augmented agents read via Cypher, SPARQL, or REST. GraphRAG-style retrieval returns subgraphs, not paragraph chunks.
AI agents use the same write paths as human editors. Whatever review workflows you've configured apply to them: live-immediately by default, stricter if you want. Adjustable AI delegation is on the roadmap: from review-every-change to just-do-it, with batch operations and previews.
Bring your own AI.
Federated and standards-aware
NeoWiki Schemas define your data model. Mappings translate it to and from standard vocabularies (CIDOC-CRM, Dublin Core, EDM, MARC/BIBFRAME, others) for RDF export and import. Both can be packaged and shared across wikis.
Federation across partner systems lets each institution keep its own data while queries reach across them. Round-tripping with Wikidata and Wikibase is on the roadmap: data flowing both ways.
The UI is internationalized; multilingual data labels and values are supported.
Provenance and governance
Every structured-data edit is versioned and attributed: who changed what, when. Schema constraints are checked at every write, not just in the form; you choose whether violations block or just flag. Subjects and Relations have stable identifiers, so references survive page moves and renames.
On the roadmap: rights statements and chain-of-production tracking for cultural-heritage publishing; per-subject and per-property access controls beyond the page level.
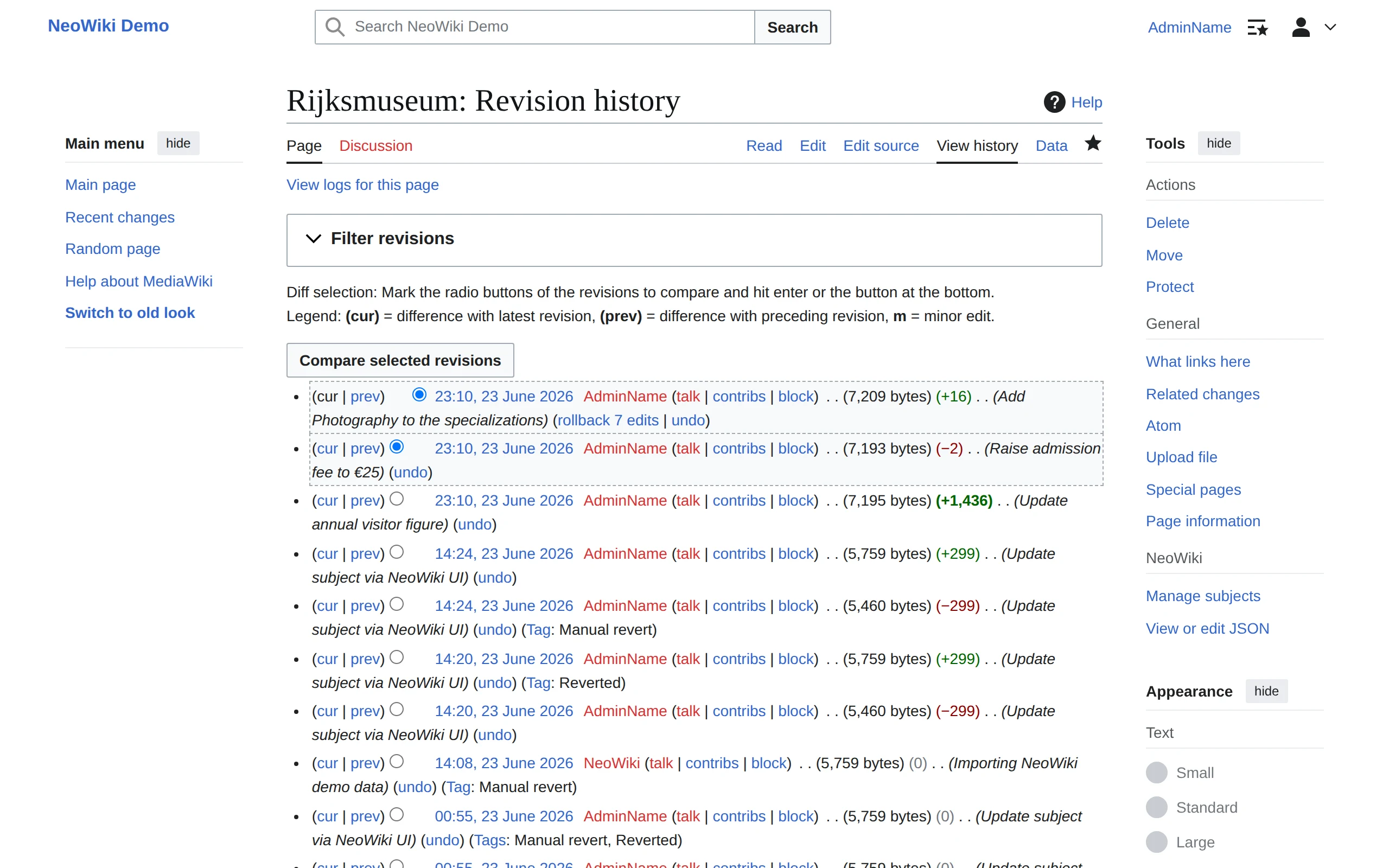
Power without engineering tickets
Your team builds custom, data-driven pages directly in NeoWiki.
Layouts control how each Subject type displays: which properties show, in what order, with what formatting, no code required. A scripting layer goes further: it reads your structured data, runs queries, and renders the results inline on any page.
Under the hood, that scripting layer is MediaWiki's templates, Lua, and parser functions, now able to read Subjects and run Cypher. Existing templates and Lua modules keep working.
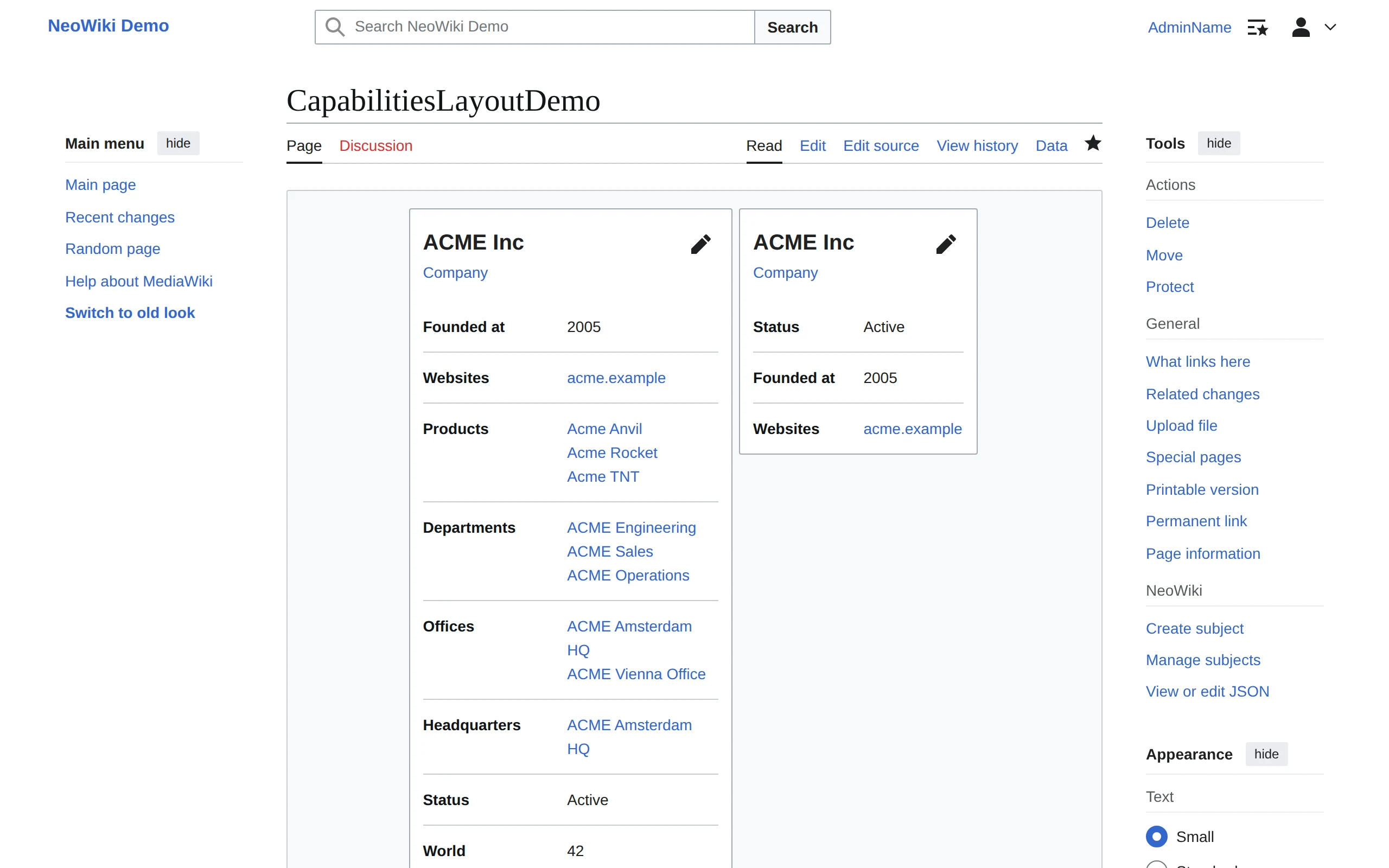
Yours to build on
The REST API exposes Subjects, Schemas, and Statements with full CRUD and query. Batch import/export APIs handle JSON and CSV for bulk operations by scripts or AI agents.
The View Type plugin handles custom Subject renderings. The Property Type plugin handles custom value types and editor UIs. Extensions can reuse NeoWiki's frontend components: Subject views, Schema forms, query renderers.
The MediaWiki MCP server exposes the wiki to agent tools over the standard Model Context Protocol.
GET /rest.php/neowiki/v0/subject/s1abc5def6ghi78
GET /rest.php/neowiki/v0/schema/CompanySovereign by design
Your data stays yours: no telemetry, no third-party services, no phone home. Standards-based exports (RDF, JSON, CSV) mean no lock-in. GDPR-aware by design.
NeoWiki is open source on GitHub. Host it yourself, or use our managed NeoWiki Hosting.